Я прочитал исходники llama.cpp.
Шестьдесят тысяч строк C++, которые в одиночку сделали локальный инференс LLM возможным на ноутбуке. Это не «лучшие практики из учебника» — это код, где каждая строка отвечает за то, чтобы умножение матриц не вылезло из L2-кэша и не съело всю пропускную способность RAM.
Я пишу на PHP. На языке, где каждое значение завёрнуто в zval, у каждого объекта 30+ байт хедера, а любой foreach аллоцирует hash iterator. Сравнение нечестное по определению. Но мне стало интересно: какие из трюков llama.cpp вообще выживут после пересадки? И что случится, если поднять датасет до миллиарда записей?
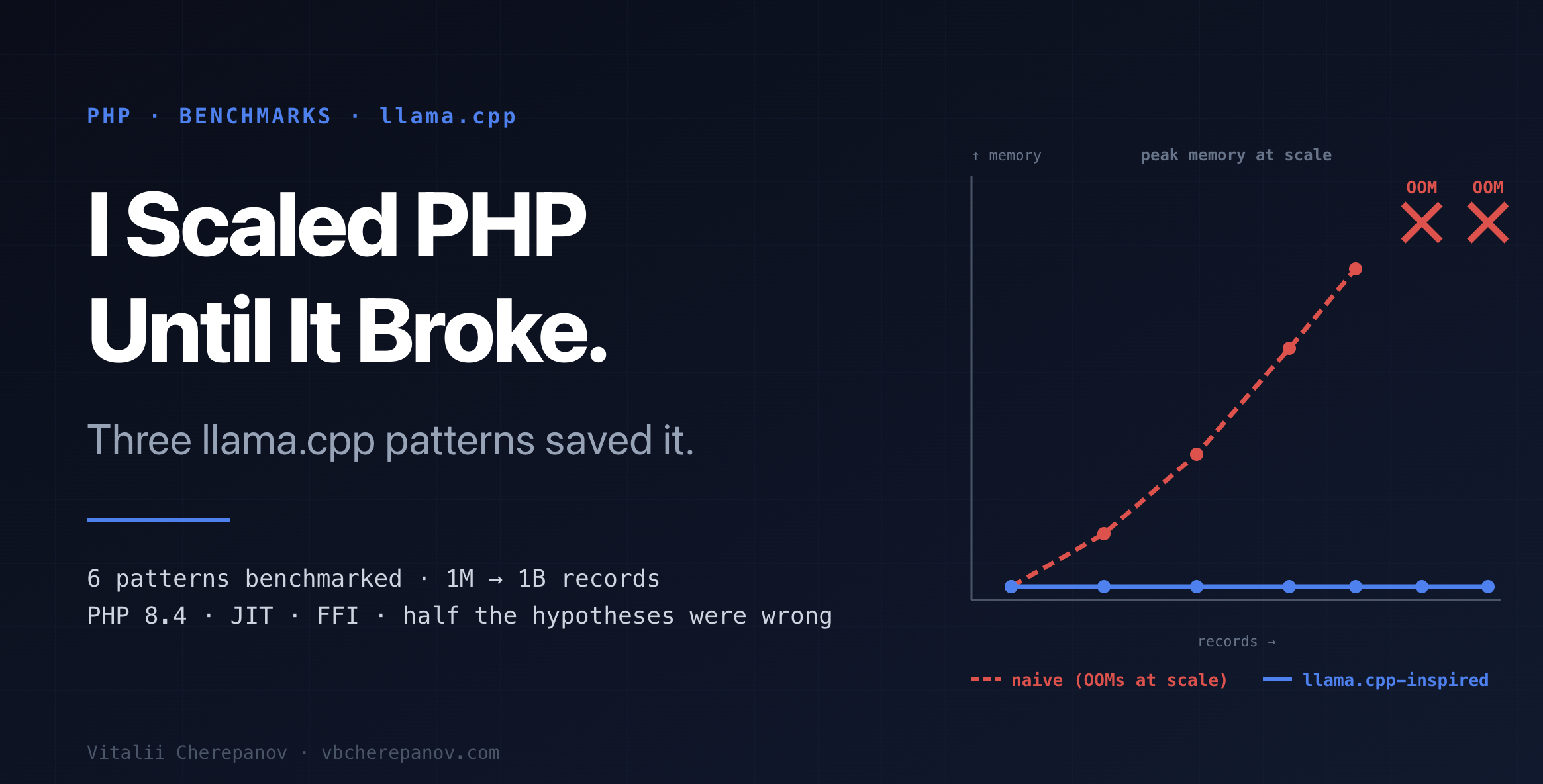
Я собрал бенчмарк-сьют. Шесть оптимизаций из llama.cpp, переведённых в PHP 8.4 с JIT. Реальные числа, статистическая методология, p99 latency. Потом масштабировал вход от 1 миллиона до 1 миллиарда записей, чтобы увидеть, где трюки перестают быть «приятными бонусами» и становятся единственным путём, по которому код вообще доезжает.
Половина моих гипотез оказалась неверной. Вот это и есть главная история.
TL;DR
| Паттерн | На 10М записей | На 100М+ | Вердикт |
|---|---|---|---|
| B01: mmap-таблица | на вызов в 7× медленнее | загрузка в 226× быстрее, 0 в PHP heap | Win на уровне процесса, не вызова |
| B02: SplFixedArray vs array | медленнее, экономия памяти 1.68× | оба доезжают до 1B; разрыв 9 ГБ | Память — да, скорость — никогда |
| B03: Object pool в hot loop | в 4.43× быстрее | масштабируется линейно | Юзать в long-running воркерах |
| B04: Lookup table vs match | lookup в 5.8× быстрее, match=switch | масштабируется линейно | Data-driven dispatch → lookup |
| B05: Generator vs полный массив | в 1.24× быстрее, память O(1) | наивный OOM, генератор доезжает | Инструмент выживания |
| B06: Колоночный vs строковой layout | в 8.66× быстрее на single-col scan | наивный OOM на 100М, колонка 959мс | Инструмент выживания |
Половина паттернов на масштабе переходит из категории «оптимизация» в «единственный путь, по которому код доезжает». Половина — нет. А один паттерн (SplFixedArray) оказался полной противоположностью того, что про него писали последние десять лет.
Пройдёмся по каждому.
B01: mmap читает гигабайты быстро, но НЕ на вызов
Гипотеза: memory-mapping больших read-only таблиц быстрее, чем загрузка через json_decode. Параллель из llama.cpp — модели грузятся через ggml_mmap (см. src/llama-mmap.cpp), а не fread в malloc-нутый буфер.
Перевод в PHP: открыть libc.dylib через FFI, вызвать mmap(), взять указатель, сделать FFI::cast('uint32_t*', $ptr) для типизированного доступа:
$ffi = FFI::cdef("
void *mmap(void *addr, size_t length, int prot, int flags, int fd, long offset);
int open(const char *pathname, int flags);
", "libc.dylib");
$fd = $ffi->open('data/lookup.bin', 0);
$ptr = $ffi->mmap(null, $size, 1, 2, $fd, 0);
$table = FFI::cast('uint32_t*', $ptr);
// Доступ: $table[$id * 2 + 1] возвращает значение для ключа $idРезультат на 10 миллионах записей:
- Время загрузки: JSON 454 мс vs mmap 1.1 мс → mmap в 226× быстрее на загрузке
- PHP heap после загрузки: JSON 256 МБ vs mmap 0 байт
- p99 на одну выборку: JSON 708 нс vs mmap 5.4 мкс → mmap в 7× МЕДЛЕННЕЕ на вызов
Стоп. mmap проигрывает в 7 раз на вызов. JIT настолько хорошо оптимизирует $arr[$id], что FFI-разыменование с накладными расходами на каст не выживает в плотном цикле чтения.
На 1 миллиарде записей mmap грузит 16 ГБ бинарника за 228 миллисекунд при нулевом PHP heap. JSON-путь там даже не существует — фикстура была бы 100+ ГБ JSON-текста, физически нереально сгенерировать.
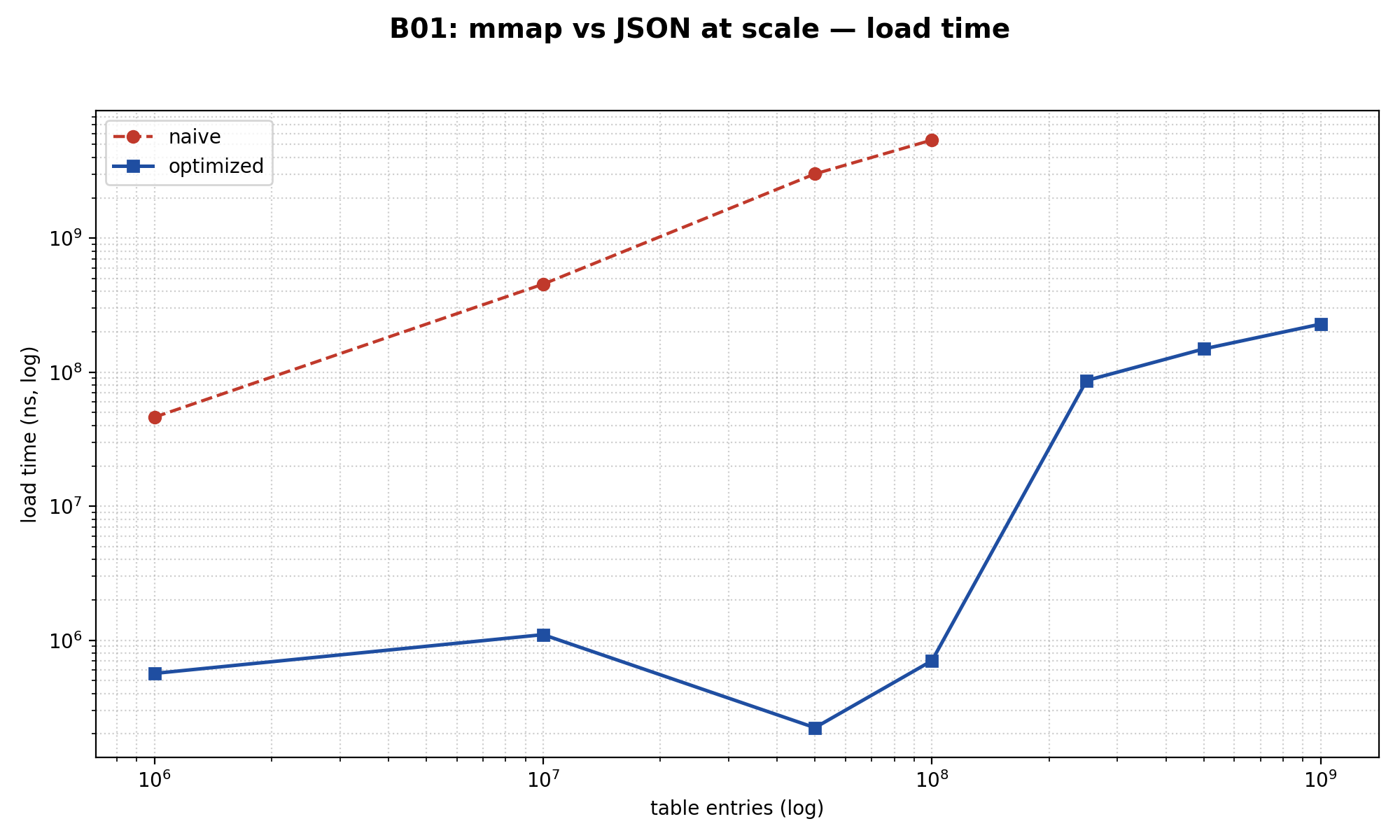
Вердикт: mmap — это не «быстрее на вызов». Это другая категория оптимизации. Она даёт время загрузки, плоский PHP heap и шаринг таблицы между N PHP-FPM воркерами через kernel page cache. Внутри одного процесса в плотном read-loop она проигрывает JIT-у. Между процессами — выигрывает на порядки: cross-process cold start второго воркера в 2641× быстрее, потому что страницы уже в kernel page cache.
Используй mmap, когда флот воркеров шарит толстую read-only таблицу. Не используй его для плотных read-loop внутри одного процесса.
B02: SplFixedArray экономит память, но никогда — скорость
Гипотеза: на плотных числовых данных SplFixedArray должен быть и быстрее (нет hash overhead), и эффективнее по памяти. Параллель из llama.cpp — ggml_tensor работает с упакованными аренами, не с массивами указателей на boxed-объекты.
Результат на 10 миллионах целых чисел:
- Память: array 256 МБ vs SFA 152 МБ → SFA экономит в 1.68×
- Iterate: array 12.2 мс vs SFA 93.8 мс → SFA в 7.7× МЕДЛЕННЕЕ
- Populate: array 56.5 мс vs SFA 108.8 мс → в 1.9× медленнее
- Случайные чтения (1М): array 23.9 мс vs SFA 98.5 мс → в 4× медленнее
Я ждал OOM-перехода и поднял свип до миллиарда целых, надеясь, что обычный массив упрётся в потолок RAM. Не упёрся. На 1B элементов: array 24 ГБ peak vs SFA 14.9 ГБ. Отставание SFA по скорости держалось на каждом тире.
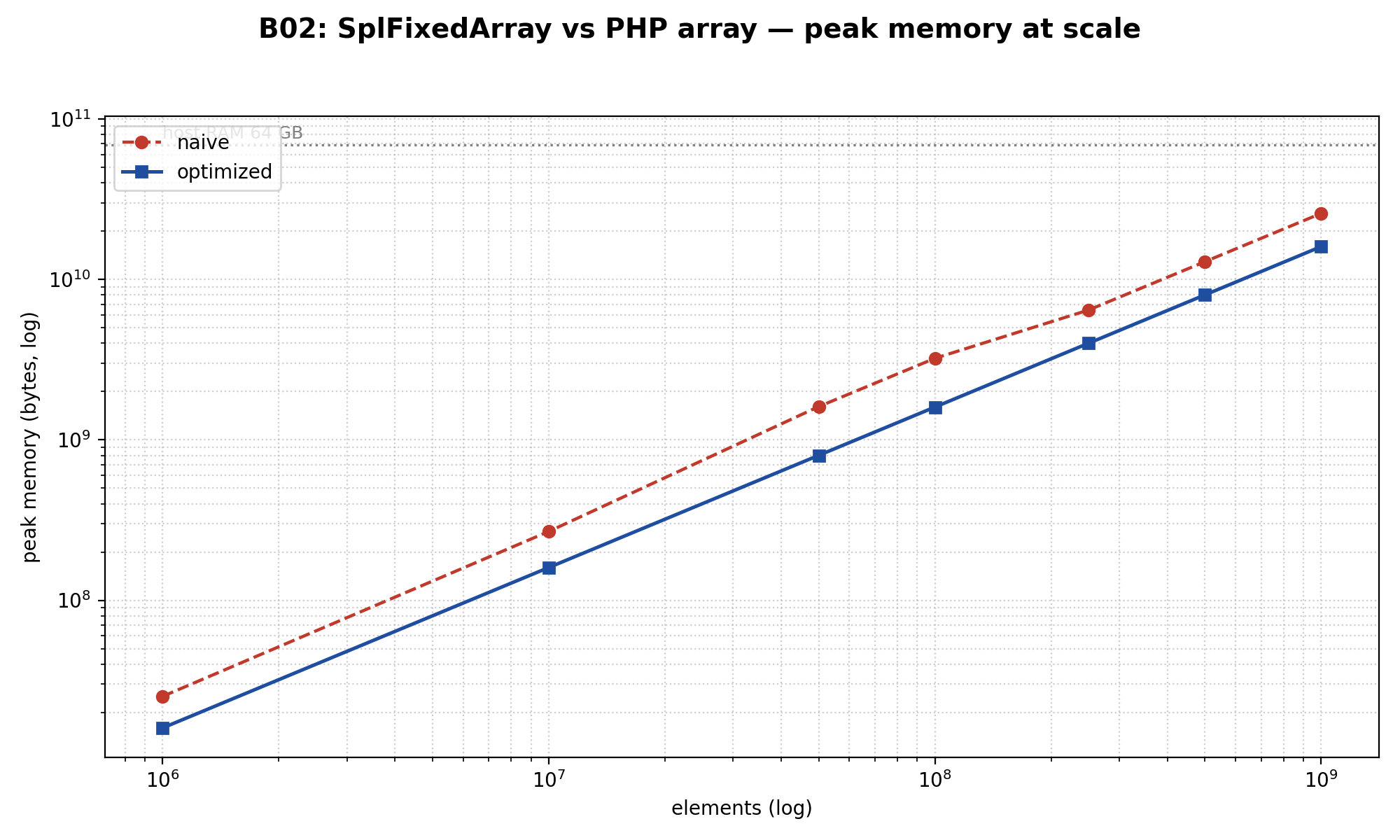
Вердикт: SplFixedArray на современном PHP — это «только память», никогда не «скорость». Народный рецепт «используй SplFixedArray для больших числовых данных, потому что быстрее» — это совет 2014 года. JIT в PHP 8.4 оптимизирует упакованные integer-keyed массивы настолько агрессивно, что специализированная структура проигрывает универсальной. Тянись за SFA, когда упёрся в память внутри long-running воркера. Прироста скорости не жди.
Это самый контринтуитивный результат в статье. Я сам не поверил и перегнал весь свип ещё дважды. Числа держатся.
B03: Object pool — единственная классическая оптимизация, которая всё ещё окупается
Гипотеза: в hot loop переиспользование маленького пула преаллоцированных объектов быстрее, чем new на каждой итерации. Параллель из llama.cpp — tensor allocator никогда не дёргает malloc внутри inner loop. Он работает против преаллоцированной арены через ggml_new_tensor_impl.
Перевод: пул из 5 инстансов Point3D, переиспользуемых через прямое присваивание свойств:
final class Point3D {
public function __construct(
public float $x = 0.0,
public float $y = 0.0,
public float $z = 0.0,
) {}
}
$pool = array_map(fn() => new Point3D(), range(0, 4));
$idx = 0;
for ($i = 0; $i < 5_000_000; $i++) {
$p = $pool[$idx++ % 5];
$p->x = $x; $p->y = $y; $p->z = $z;
// ... работаем с $p
}Результат на 5 миллионах аллокаций: наивный 813 мс vs пул 179 мс → в 4.43× быстрее.
GC-циклов: ноль в обоих случаях. Point3D нециклический, GC PHP не срабатывает. Вся экономия — на пути аллокатора: new в Zend Engine — лёгкий, но ненулевой code path (zend_object_new → emalloc → инициализация свойств × N). Пять миллионов раз — это уже заметно.
Вердикт: работает как ожидалось. В CLI-скриптах win реальный, но не критичный. В long-running воркерах (очереди, websocket, демоны) tail latency от давления аллокатора накапливается со временем и становится головной болью — вот там пулинг окупается.
B04: Lookup table бьёт match и switch (а эти двое равны)
Гипотеза: для dispatch-логики с 16+ кейсами в hot loop array lookup бьёт match и switch. Параллель из llama.cpp — token dispatch в llama_token_to_piece использует таблицы, не switch-и.
Перевод: классификатор на 32 кейса, реализованный тремя способами — switch, match и преднабранный $lookup = [0 => 'A', 1 => 'B', ...].
Результат на 10 миллионах диспетчей:
switch: 358 мс (27.9М ops/sec)match: 365 мс (27.4М ops/sec)lookup: 61.7 мс (162М ops/sec) — в 5.8× быстрее
match и switch равны. Оба компилируются в одну и ту же jump table для integer-кейсов. JIT в PHP 8.4 шлифует обе формы до одинакового результата. Если ты переписал switch на match ради «модернизации» — ты получил читабельность, не скорость.
Где win lookup испаряется: если dispatch выдаёт строку для последующих === сравнений, выигрыш съедают строковые сравнения дальше по пайплайну.
Вердикт: match-shaped задачи (закрытое compile-time множество, нужна exhaustiveness) остаются в match. Data-driven dispatch (таблица из конфига, генерируемая в runtime) — в lookup. Дебаты «match vs switch для перфа» закрыты — они эквивалентны.
B05: Generator — главный инструмент выживания на больших стримах
Гипотеза: генератор снижает peak memory с O(N) до O(1) при незначительной потере throughput. Параллель из llama.cpp — токены стримятся через callback, а не накапливаются в буфере (llama_decode → llama_get_logits_ith).
Перевод в PHP: заменить function process(): array на function process(): Generator:
function records(): Generator {
foreach (read_csv('data.csv') as $row) {
yield ['id' => $row[0], 'value' => $row[1]];
}
}Результат на 5 миллионах записей:
- Wall time: наивный 525 мс vs gen 449 мс → gen в 1.24× быстрее
- Peak memory: наивный 1.88 ГБ vs gen 0 байт PHP heap
Генератор не просто экономит память — он ещё и быстрее по wall time, потому что массив никогда не нужно полностью материализовать до начала обработки.
А теперь масштаб. На 100 миллионах записей наивный — OOM, ядро шлёт SIGKILL после 28.6 секунд. Генератор доезжает те же 100М за 10.4 секунды при нулевом PHP heap. На 500М генератор всё ещё работает (45.7 секунды). Наивный даже не пробует.
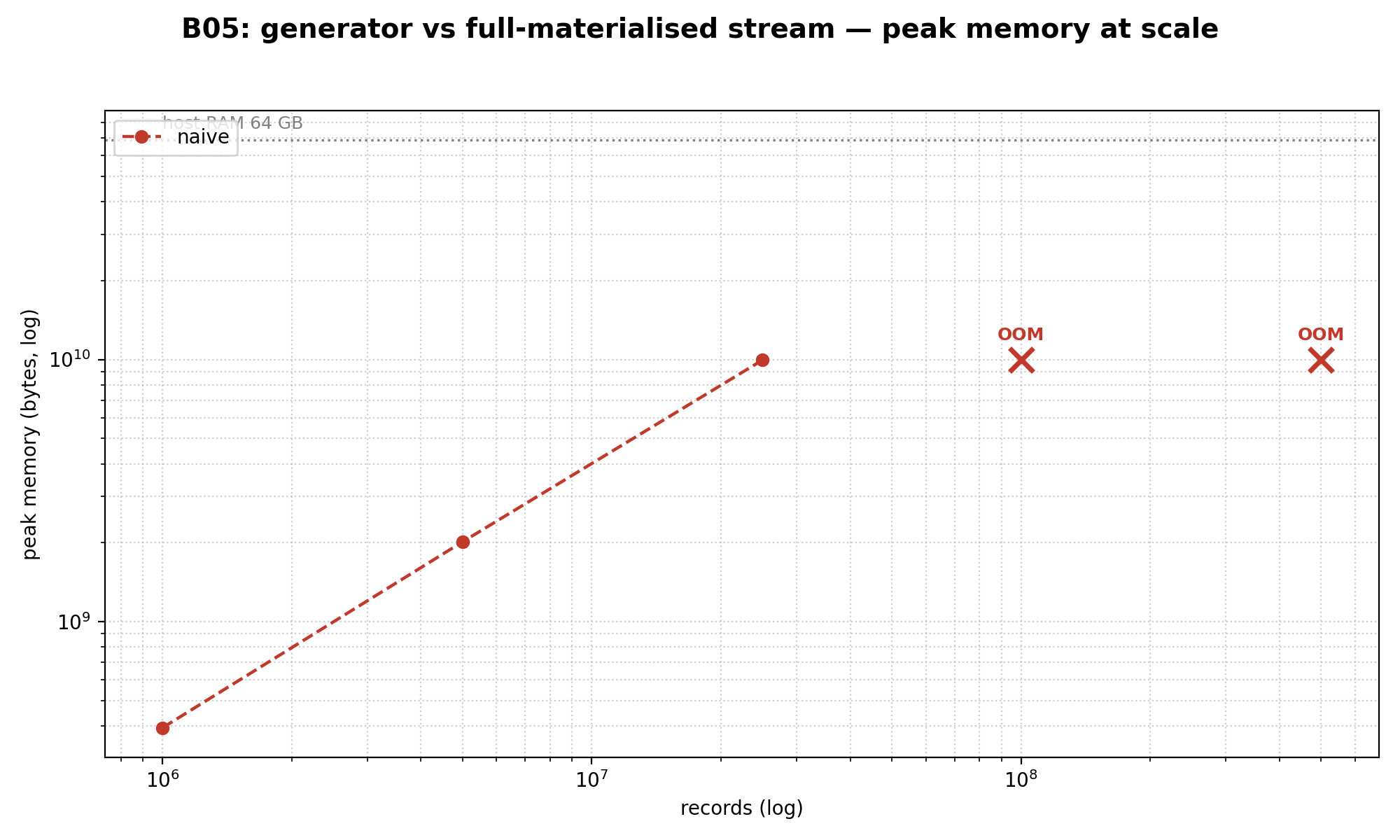
Если бы пришлось вытащить из всей статьи одну фразу и повесить на баннер — это была бы она:
На 100 000 записей генератор — это 1.24× nice-to-have. На 100 миллионах — это единственный путь, по которому код вообще доезжает.
Вердикт: дефолт для любого single-pass потока, к которому не надо возвращаться. Материализуй массив только когда нужны random access, несколько проходов или count() до обработки.
B06: Колоночный layout — это не про cache locality, а про побег от боксинга
Гипотеза: на аналитических single-column сканах колоночный layout быстрее строкового из-за cache locality. Параллель из llama.cpp — тензоры хранятся per-channel (SoA), не per-element (AoS).
Перевод в PHP: вместо SplFixedArray из stdClass с 5 полями — 5 параллельных SplFixedArray, по одному на поле:
// Строковый layout (наивный)
$rows = new SplFixedArray($n);
for ($i = 0; $i < $n; $i++) {
$obj = new stdClass();
$obj->f1 = ...; $obj->f2 = ...; /* ... */ $obj->f5 = ...;
$rows[$i] = $obj;
}
$sum = 0;
foreach ($rows as $r) $sum += $r->f3;
// Колоночный layout (оптимизированный)
$f3 = new SplFixedArray($n); // и так для каждого поля
for ($i = 0; $i < $n; $i++) $f3[$i] = ...;
$sum = 0;
for ($i = 0; $i < $n; $i++) $sum += $f3[$i];Результат на 5 миллионах записей: колоночный в 8.66× быстрее на single-column scan. На full-row scan (sum f1..f5) — в 1.92× быстрее.
И вот тут начинается самое интересное. Я ждал ступенек на графике ns/record — там, где working set перестаёт влезать в L1, потом в L2, потом в L3. Я их не увидел. Кривые плоские во всём диапазоне 100K → 100M: колонка держится на ~9.5–11.5 нс/запись. Строка — на ~80–93 нс/запись. Никаких ступеней.
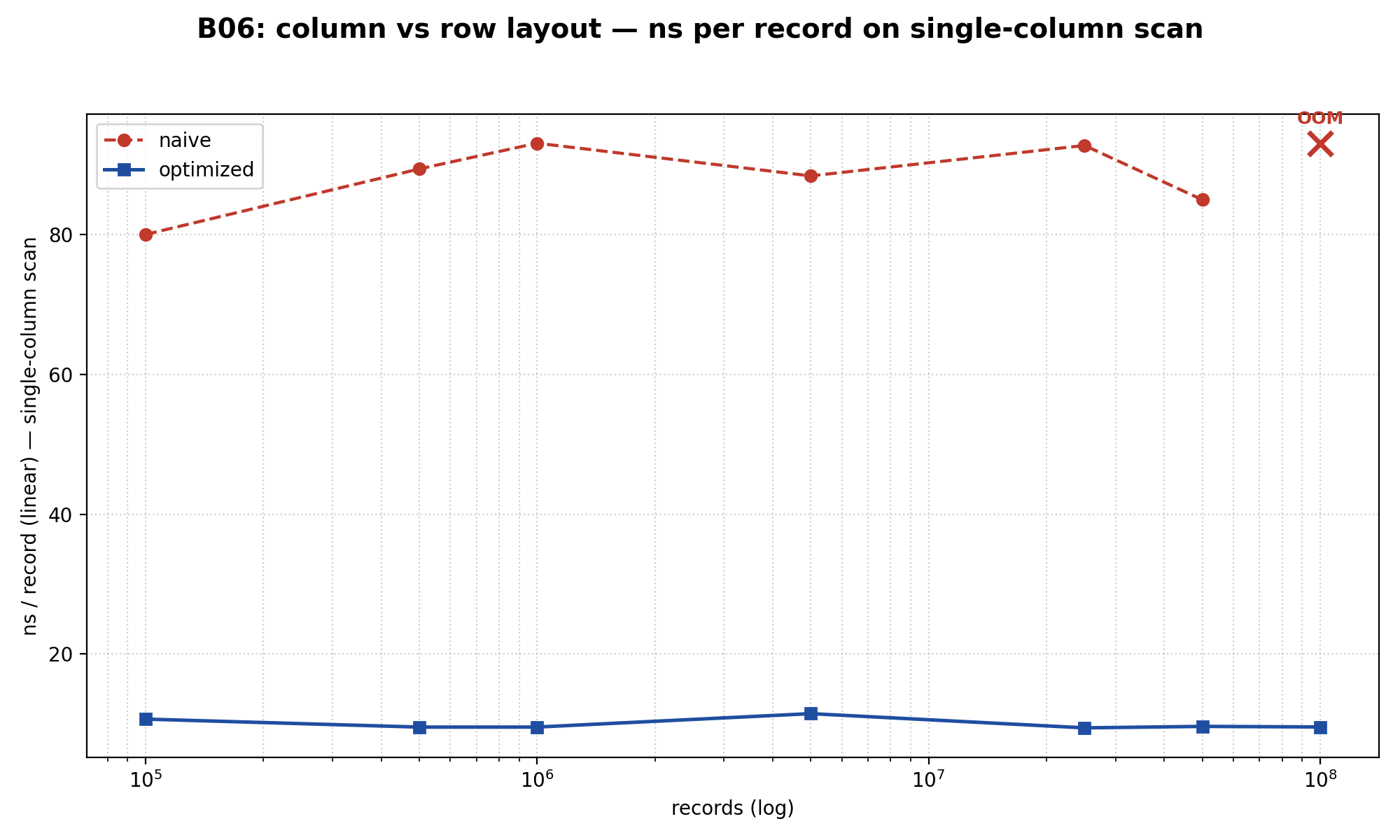
Это более сильный инсайт, чем «вот ступеньки». Кэш-эффекты внутри обоих layout-ов их не различают. Различает их сам layout. Строковый тратит ~30+ байт на каждый stdClass (zval header + property table + GC info) ради 8 байт реальных данных. На 100М записей это 28 ГБ только на боксинг. Колоночный на тех же 100М — 7.45 ГБ, потому что каждая колонка — упакованный SplFixedArray без боксинга.
На 100М записей строковый — OOM, 28+ ГБ stdClass-объектов не влезают. Колоночный заканчивает скан за 959 миллисекунд при 7.45 ГБ.
Вердикт: колоночный layout — это не cache-оптимизация (как я думал). Это побег от overhead PHP-объектов на масштабе. На любой аналитической нагрузке поверх больших датасетов — колоночный. Строковый остаётся уместным, когда DTO передаются между слоями или когда working set маленький.
Что происходит на масштабе
Микро-бенчмарки на 1–10 млн элементов рисуют одну картину. Масштаб до миллиардов — другую.
Три из шести паттернов на больших данных переходят из «оптимизации» в «необходимость»:
- B05 generator — на 100М наивный — OOM. Генератор доезжает.
- B06 колоночный layout — на 100М строковый — OOM. Колоночный заканчивает скан за 959 мс.
- B01 mmap — на 1B JSON-фикстура физически не существует (100+ ГБ). mmap грузит 16 ГБ бинарника за 228 мс.
Два паттерна остаются «просто оптимизациями» независимо от масштаба:
- B03 object pool: ~4× на любом размере.
- B04 lookup table: ~5× на любом размере.
Один паттерн оказался узким — экономит память, но не скорость:
- B02 SplFixedArray: на 38% меньше памяти, всегда медленнее по скорости. Оба пути работают вплоть до 1B.
Это, пожалуй, самый важный реверс в статье. Когда кто-то говорит «X быстрее, чем Y» — это утверждение про конкретный размер данных. На малых данных половина утверждений ломается. На больших — половина из них превращается в «X работает, Y не существует».
И ещё одно, отдельной строкой: JIT в PHP 8.4 продолжает съедать оптимизации с каждым релизом. Между прогонами на PHP 8.3.31 и 8.4.21 B03 ускорился с 2.78× до 4.43×, B04 — с 3.75× до 5.81×. Не баг — JIT просто продолжает улучшаться. Через год эти числа снова сместятся.
Три правила производительности PHP в 2026
Из этих шести экспериментов сложился рабочий фреймворк.
1. Доверяй JIT.
Не пытайся переиграть его на синтаксическом уровне. match vs switch — JIT компилирует обе формы в одну jump table. SplFixedArray vs упакованный массив — JIT оптимизирует обычный массив настолько агрессивно, что специализированная структура проигрывает по скорости. FFI dereference vs $arr[$id] — JIT-компилированный array access бьёт FFI-касты внутри hot loop.
Если твоя оптимизация про «какую языковую конструкцию выбрать» — JIT уже сделал этот выбор за тебя.
2. Оптимизируй то, что JIT не видит.
- Cache locality (B06: колоночный layout) — JIT не управляет memory layout. Это твоя архитектура.
- Allocation pressure (B03: object pool) — JIT не убирает аллокации, он их ускоряет.
- I/O batching (батчевый INSERT 1000 строк vs single-row) — JIT не оптимизирует round trips в Postgres.
- Cross-process resource sharing (B01: mmap + page cache) — JIT работает per process.
- Streaming vs materialization (B05: generator) — JIT не уберёт за тебя 30 ГБ peak memory.
3. На достаточно большом масштабе оптимизации перестают быть оптимизациями.
Они становятся порогом выживания. Генератор на 100K записей — в 1.24× быстрее. На 100М — единственный код, который доезжает. Колоночный layout на 5М — в 8.66× быстрее. На 100М — единственный код, который не съедает 28 ГБ на overhead stdClass. mmap на 10М — медленнее на вызов. На 1B — единственный способ загрузить таблицу за секунду.
Это структурное мышление, не синтаксическое. И именно это превращает llama.cpp из «сильно оптимизированной C++ библиотеки» в учебный артефакт для PHP-разработчика. Не «вот трюки, тащи». А «вот пределы языка, которые видны только когда в них врежешься».
Закрытие
Весь код бенчмарков и воспроизводимый Docker-сетап лежат на GitHub: vbcherepanov/php-llamacpp-benchmarks. Полный свип занимает ~15 минут (make all), включая case study с импортом 100K строк в реальный PostgreSQL.
Замечание про репу: директория data/ в gitignore — фикстуры (до 16 ГБ бинарных lookup-файлов на 1B-тире) генерятся локально через make fixtures. Не пытайтесь клонировать с ними.
Если найдёте баг в методологии или захотите добавить тир — присылайте PR. Я вожусь с такими вещами через Braincore — Go-meta-агент с cost-aware роутингом и слоем памяти для AI-кодинг-агентов. Если бенчмарки оказались полезны и хотите поддержать продолжение — есть Ko-fi.