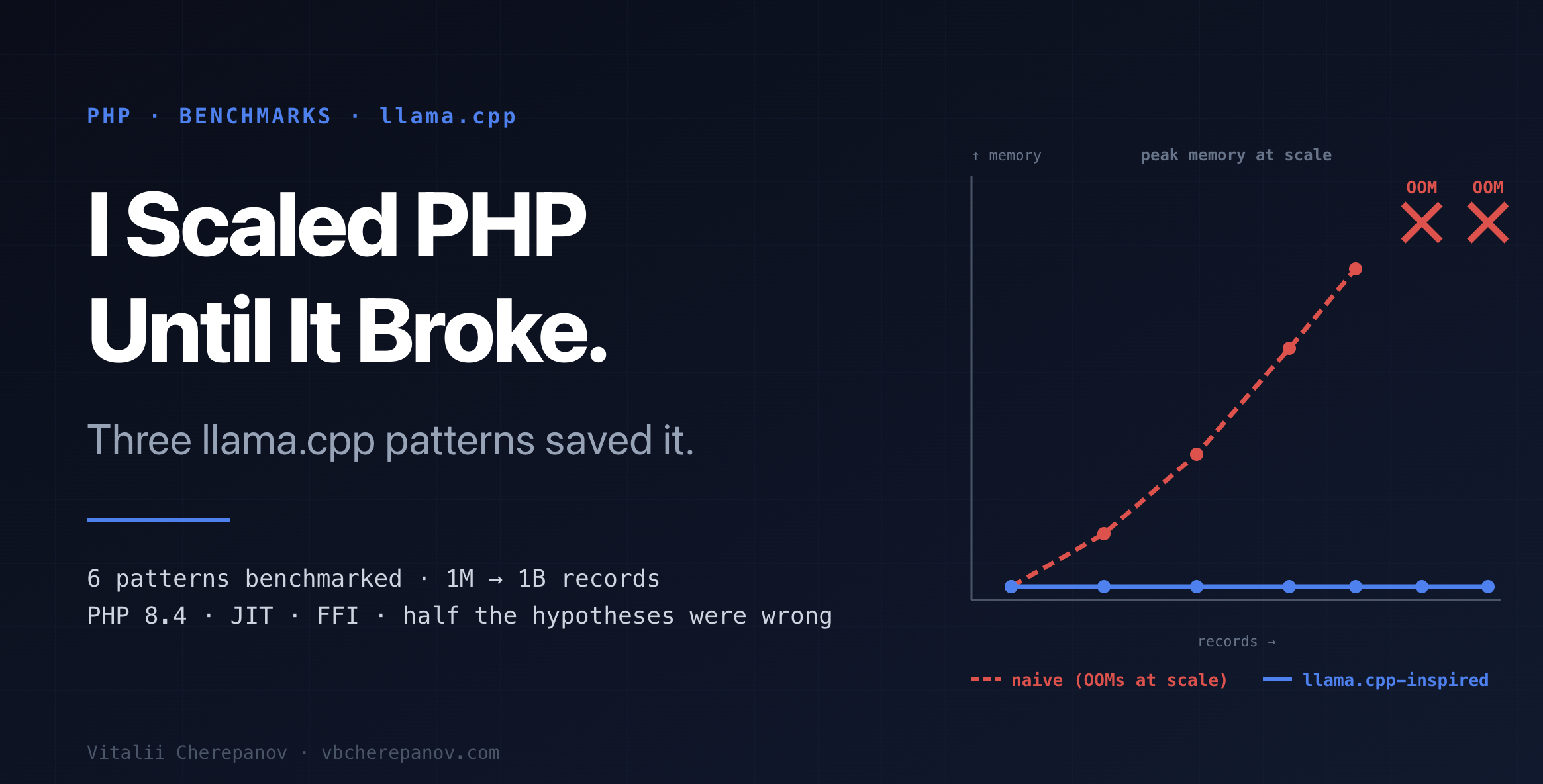
Pročitao sam izvorni kod llama.cpp.
Šezdeset hiljada linija C++ koda koje su same omogućile lokalni LLM inference na laptopu. Ovo nisu „best practice iz udžbenika” — to je kod gde je svaka linija odgovorna za to da množenje matrica ostane unutar L2 keša i van budžeta propusnog opsega RAM-a.
Pišem PHP. Jezik gde je svaka vrednost umotana u zval, svaki objekat nosi 30+ bajtova hedera, a svaki foreach alocira hash iterator. Poređenje je nepravedno po definiciji. Ali bilo mi je radoznalo: koji od trikova llama.cpp-a uopšte preživi presađivanje? I šta će se desiti kada gurnem dataset do milijardu zapisa?
Napravio sam benchmark suite. Šest optimizacija iz llama.cpp-a, prevedenih u PHP 8.4 sa JIT-om. Realni brojevi, statistička metodologija, p99 latencije. Onda sam skalirao input od 1 miliona do 1 milijardu zapisa, da vidim gde trikovi prestaju da budu „prijatan dodatak” i postanu jedini put kojim kod uopšte može da završi.
Polovina mojih hipoteza je bila pogrešna. To je prava priča.
TL;DR
| Patern | Na 10M zapisa | Na 100M+ | Verdikt |
|---|---|---|---|
| B01: mmap tabela | po pozivu 7× sporije | učitavanje 226× brže, 0 PHP heap | Win na nivou procesa, ne poziva |
| B02: SplFixedArray vs array | sporije, ušteda 1.68× memorije | oba rade do 1B; razlika 9 GB | Memorija — da, brzina — nikada |
| B03: Object pool u hot loop-u | 4.43× brže | skalira linearno | Koristi u long-running worker-ima |
| B04: Lookup table vs match | lookup 5.8× brži, match=switch | skalira linearno | Data-driven dispatch → lookup |
| B05: Generator vs pun array | 1.24× brže, memorija O(1) | naivni OOM, generator završi | Alat za preživljavanje |
| B06: Kolonski vs row layout | 8.66× brže single-col scan | naivni OOM na 100M, kolona 959ms | Alat za preživljavanje |
Polovina paterna na skali prelazi iz „optimizacija” u „jedini put kojim kod može završiti”. Polovina ne. A jedan patern (SplFixedArray) ispao je suprotno od onoga što se o njemu pisalo poslednjih deset godina.
Idemo redom.
B01: mmap čita gigabajte brzo, ali NE po pozivu
Hipoteza: memory-mapping velikih read-only tabela je brži od učitavanja preko json_decode. Llama.cpp paralela — modeli se učitavaju kroz ggml_mmap (vidi src/llama-mmap.cpp), ne kroz fread u malloc-ovan bafer.
PHP prevod: otvori libc.dylib preko FFI, pozovi mmap(), uzmi pointer, FFI::cast('uint32_t*', $ptr) za tipiziran pristup:
$ffi = FFI::cdef("
void *mmap(void *addr, size_t length, int prot, int flags, int fd, long offset);
int open(const char *pathname, int flags);
", "libc.dylib");
$fd = $ffi->open('data/lookup.bin', 0);
$ptr = $ffi->mmap(null, $size, 1, 2, $fd, 0);
$table = FFI::cast('uint32_t*', $ptr);
// Pristup: $table[$id * 2 + 1] vraća vrednost za ključ $idRezultat na 10 miliona zapisa:
- Vreme učitavanja: JSON 454 ms vs mmap 1.1 ms → mmap je 226× brži pri učitavanju
- PHP heap nakon učitavanja: JSON 256 MB vs mmap 0 bajtova
- p99 po jednom lookup-u: JSON 708 ns vs mmap 5.4 µs → mmap je 7× SPORIJI po pozivu
Stop. mmap gubi 7× po pozivu. JIT optimizuje $arr[$id] toliko dobro da FFI dereference sa cast overhead-om ne preživi tight read loop.
Na 1 milijardi zapisa, mmap učita 16 GB binara za 228 milisekundi uz nula PHP heap. JSON put tu ni ne postoji — fixture bi bila 100+ GB JSON teksta, fizički nerealno generisati.
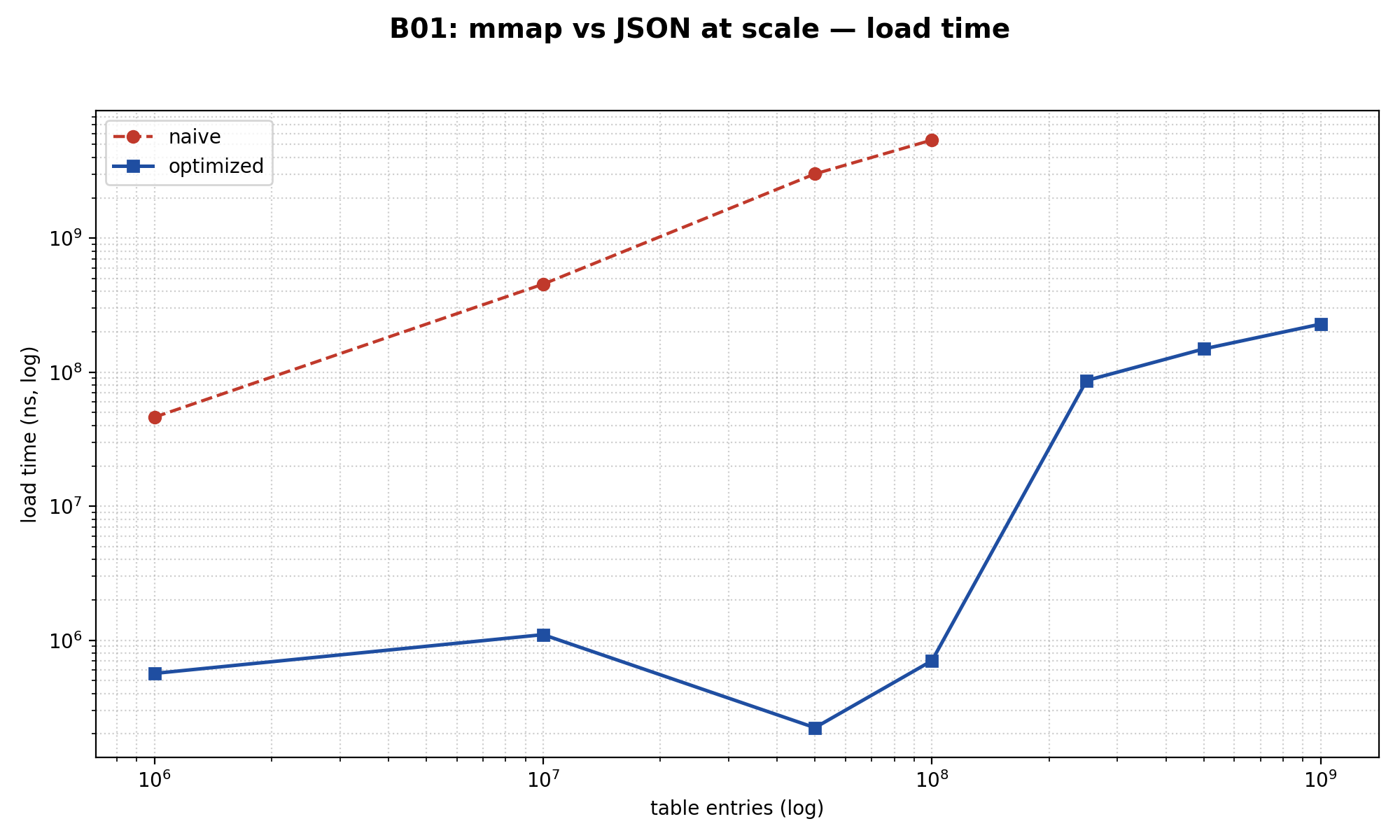
Verdikt: mmap nije „brži po pozivu”. On je druga kategorija optimizacije. Daje ti vreme učitavanja, ravan PHP heap i deljenje tabele između N PHP-FPM workera kroz kernel page cache. Unutar jednog procesa u tight read loop-u — gubi od JIT-a. Između procesa — pobeđuje za redove veličine: cross-process cold start drugog workera je 2641× brži, jer su stranice već u kernel page cache-u.
Koristi mmap kada flota workera deli debelu read-only tabelu. Ne koristi ga za tight read loop-ove unutar jednog procesa.
B02: SplFixedArray štedi memoriju, ali nikad brzinu
Hipoteza: na gustim numeričkim podacima, SplFixedArray treba da bude i brži (bez hash overhead-a) i memorijski efikasniji. Llama.cpp paralela — ggml_tensor radi sa upakovanim arenama, ne sa nizovima pointer-a na boxed objekte.
Rezultat na 10 miliona integer-a:
- Memorija: array 256 MB vs SFA 152 MB → SFA štedi 1.68×
- Iterate: array 12.2 ms vs SFA 93.8 ms → SFA je 7.7× SPORIJI
- Populate: array 56.5 ms vs SFA 108.8 ms → 1.9× sporiji
- Random reads (1M): array 23.9 ms vs SFA 98.5 ms → 4× sporiji
Očekivao sam OOM crossover, pa sam gurao sweep do milijardu integer-a nadajući se da će obični array dostići RAM plafon. Nije. Na 1B elemenata: array 24 GB peak vs SFA 14.9 GB. SFA je gubio po brzini na svakom tier-u.
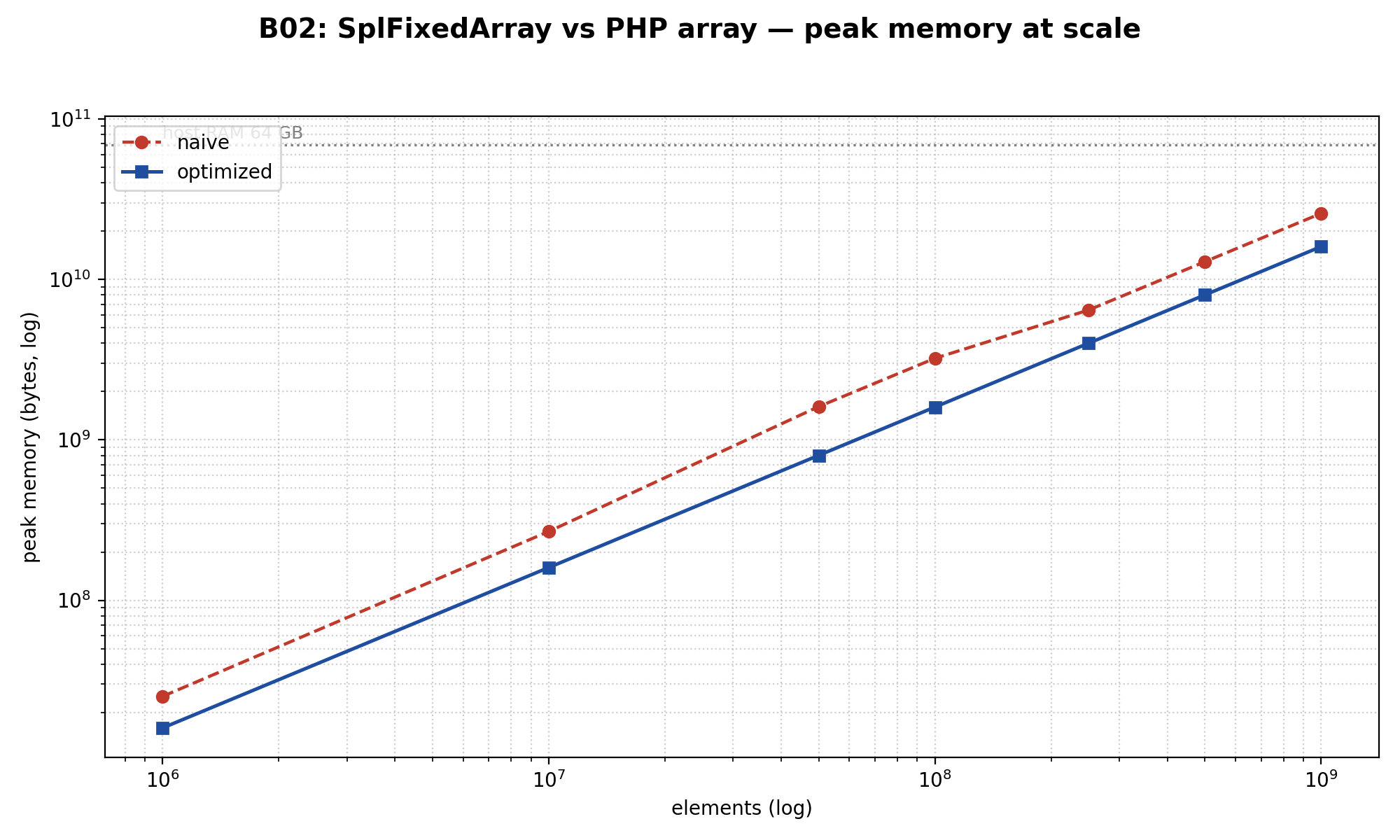
Verdikt: SplFixedArray na modernom PHP-u je samo memorija, nikada brzina. Folklor „koristi SplFixedArray za velike numeričke podatke jer je brži” — to je savet iz 2014. JIT u PHP 8.4 optimizuje upakovane integer-keyed array-e toliko agresivno da specijalizovana struktura gubi od opšte. Posegni za SFA kada si memorijski ograničen unutar long-running worker-a. Ne očekuj ubrzanje.
Ovo je najkontraintuitivniji nalaz u članku. Nisam ni sam verovao, pa sam ponovo pustio ceo sweep dva puta. Brojevi se drže.
B03: Object pool — jedina klasična optimizacija koja se još isplati
Hipoteza: u hot loop-u, ponovno korišćenje malog pula prealociranih objekata je brže od new na svakoj iteraciji. Llama.cpp paralela — tensor allocator nikad ne zove malloc unutar inner loop-a. Radi protiv prealocirane arene kroz ggml_new_tensor_impl.
Prevod: pul od 5 instanci Point3D-a, ponovo korišćen kroz direktno postavljanje properties:
final class Point3D {
public function __construct(
public float $x = 0.0,
public float $y = 0.0,
public float $z = 0.0,
) {}
}
$pool = array_map(fn() => new Point3D(), range(0, 4));
$idx = 0;
for ($i = 0; $i < 5_000_000; $i++) {
$p = $pool[$idx++ % 5];
$p->x = $x; $p->y = $y; $p->z = $z;
// ... rad sa $p
}Rezultat na 5 miliona alokacija: naivni 813 ms vs pool 179 ms → 4.43× brže.
GC ciklusa: nula u oba slučaja. Point3D nije ciklični, PHP GC se ne aktivira. Sva ušteda dolazi iz allocator path-a: new u Zend Engine-u je lagan ali ne-nulti code path (zend_object_new → emalloc → property init × N). Pet miliona puta — to se zbraja.
Verdikt: radi kao što se očekuje. U CLI skriptama win je realan ali ne kritičan. U long-running worker-ima (queue, websocket, daemon), tail latency od pritiska allocator-a se nakuplja vremenom i postaje glavobolja — tu se pooling isplati.
B04: Lookup table pobeđuje match i switch (a ova dva su jednaka)
Hipoteza: za dispatch logiku sa 16+ slučajeva u hot loop-u, array lookup pobeđuje match i switch. Llama.cpp paralela — token dispatch u llama_token_to_piece koristi tabele, ne switch-eve.
Prevod: klasifikator sa 32 slučaja implementiran na tri načina — switch, match i preunbild $lookup = [0 => 'A', 1 => 'B', ...].
Rezultat na 10 miliona dispatch-eva:
switch: 358 ms (27.9M ops/sec)match: 365 ms (27.4M ops/sec)lookup: 61.7 ms (162M ops/sec) — 5.8× brže
match i switch su izjednačeni. Oba se kompajliraju u istu jump tabelu za integer slučajeve. PHP 8.4 JIT poliše obe forme do istog rezultata. Ako si prepravio switch u match zbog „modernizacije” — dobio si čitljivost, ne brzinu.
Gde lookup win nestaje: ako dispatch proizvede string za downstream === poređenja, dobitak pojedu string poređenja niz pipeline.
Verdikt: match-shaped problemi (zatvoren compile-time skup, traži se exhaustiveness) ostaju u match. Data-driven dispatch (tabela učitana iz konfiga, generisana u runtime-u) ide u lookup. Debata „match vs switch za perf” je zatvorena — ekvivalentni su.
B05: Generator — glavni alat za preživljavanje na velikim stream-ovima
Hipoteza: generator smanjuje peak memoriju sa O(N) na O(1) uz sitnu kaznu po throughput-u. Llama.cpp paralela — tokeni se stream-uju kroz callback umesto da se akumuliraju u baferu (llama_decode → llama_get_logits_ith).
PHP prevod: zameni function process(): array sa function process(): Generator:
function records(): Generator {
foreach (read_csv('data.csv') as $row) {
yield ['id' => $row[0], 'value' => $row[1]];
}
}Rezultat na 5 miliona zapisa:
- Wall time: naivni 525 ms vs gen 449 ms → gen 1.24× brži
- Peak memorija: naivni 1.88 GB vs gen 0 bajtova PHP heap-a
Generator nije samo manje-memorijski — on je i brži po wall time-u, jer array nikada ne mora biti potpuno materijalizovan pre nego što obrada počne.
Sad skala. Na 100 miliona zapisa, naivni — OOM, kernel ubija proces sa SIGKILL nakon 28.6 sekundi. Generator završava istih 100M za 10.4 sekunde uz nula PHP heap. Na 500M, generator još uvek radi (45.7 sekundi). Naivni i ne pokušava.
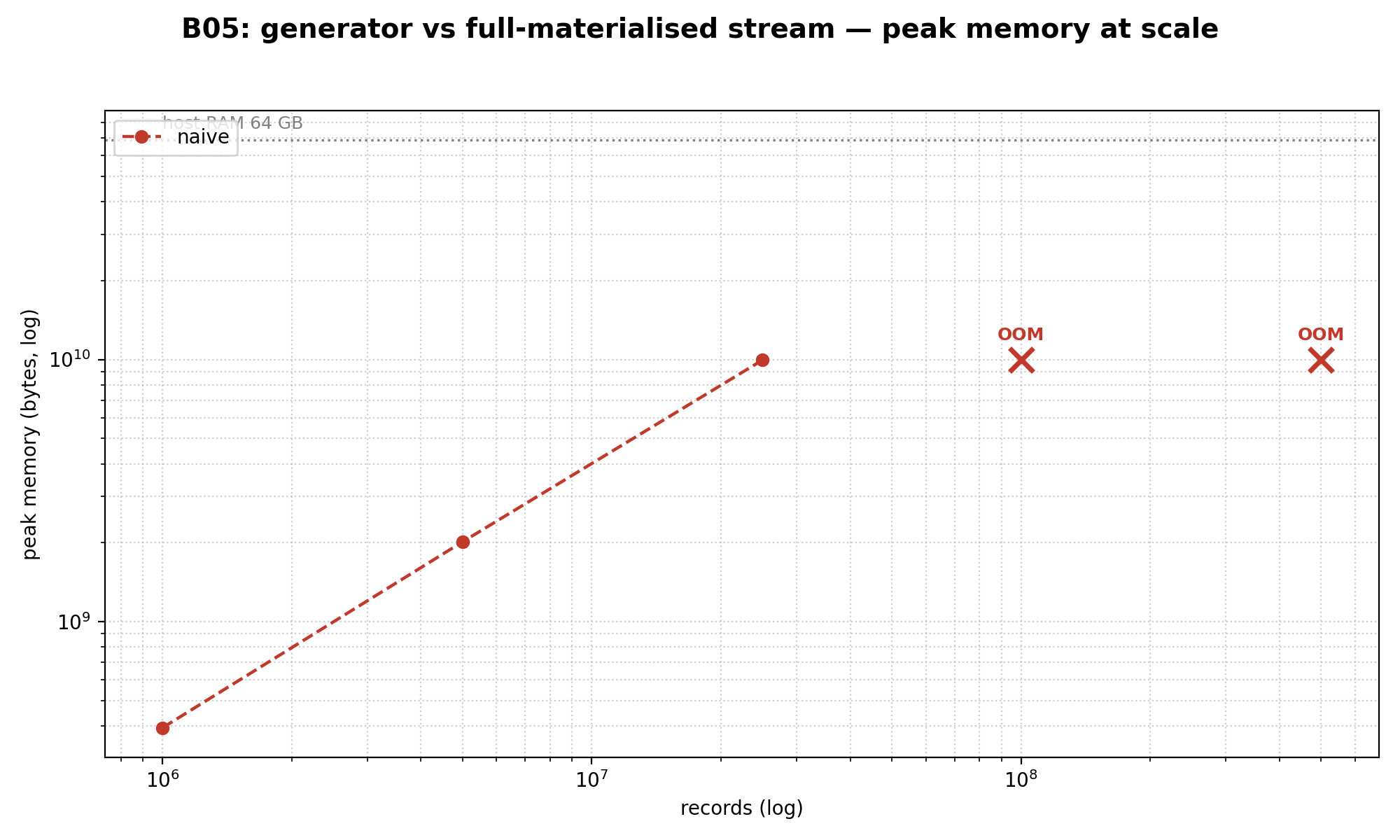
Da moram da izvučem jednu rečenicu iz cele ove statije i stavim je na baner, bila bi ova:
Na 100.000 zapisa, generator je 1.24× nice-to-have. Na 100 miliona, on je jedini put kojim kod može završiti.
Verdikt: podrazumevani izbor za bilo koji single-pass stream koji ne moraš ponovo da posetiš. Materijalizuj array samo kada ti treba random access, više prolaza ili count() pre obrade.
B06: Kolonski layout — nije cache locality, nego beg od boxing-a
Hipoteza: na analitičkim single-column skenovima, kolonski layout je brži od row-orientisanog zbog cache locality. Llama.cpp paralela — tenzori se čuvaju per-channel (SoA), ne per-element (AoS).
PHP prevod: umesto SplFixedArray od stdClass sa 5 polja — 5 paralelnih SplFixedArray instanci, po jedna za svako polje:
// Row-orientisani (naivni)
$rows = new SplFixedArray($n);
for ($i = 0; $i < $n; $i++) {
$obj = new stdClass();
$obj->f1 = ...; $obj->f2 = ...; /* ... */ $obj->f5 = ...;
$rows[$i] = $obj;
}
$sum = 0;
foreach ($rows as $r) $sum += $r->f3;
// Kolonski (optimizovan)
$f3 = new SplFixedArray($n); // i tako za svako polje
for ($i = 0; $i < $n; $i++) $f3[$i] = ...;
$sum = 0;
for ($i = 0; $i < $n; $i++) $sum += $f3[$i];Rezultat na 5 miliona zapisa: kolonski je 8.66× brži na single-column skenu. Na full-row skenu (sum f1..f5) — 1.92× brži.
I tu postaje zanimljivo. Očekivao sam stepenice na ns/record grafu — gde working set prestaje da staje u L1, pa u L2, pa u L3 keš. Nisam ih video. Krive su ravne kroz ceo opseg 100K → 100M: kolona se drži na ~9.5–11.5 ns/record. Row na ~80–93 ns/record. Bez stepenica.
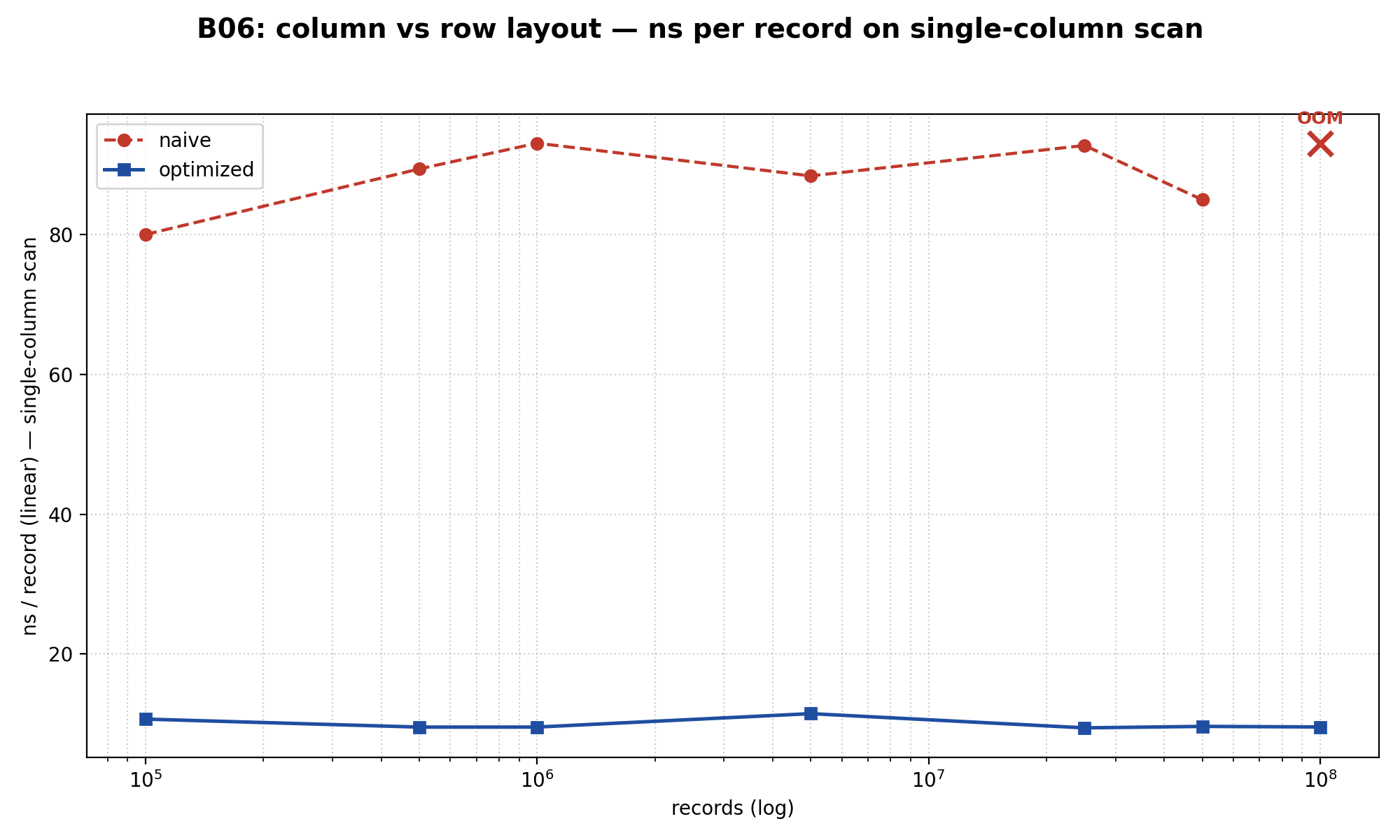
Ovo je jači uvid od „evo stepenica”. Cache efekti unutar oba layout-a ih ne razlikuju. Razlikuje ih sam layout. Row-orientisani troši ~30+ bajtova po stdClass-u (zval header + property table + GC info) za 8 bajtova stvarnog payload-a. Na 100M zapisa to je 28 GB samo na boxing. Kolonski na istih 100M = 7.45 GB, jer je svaka kolona upakovan SplFixedArray bez boxing-a.
Na 100M zapisa, row — OOM, 28+ GB stdClass objekata ne staje. Kolonski završava sken za 959 milisekundi uz 7.45 GB.
Verdikt: kolonski layout nije cache optimizacija (kako sam pretpostavio). To je beg od overhead-a PHP objekata na skali. Na bilo kom analitičkom radnom opterećenju nad velikim setovima podataka — kolonski. Row ostaje primeren kada se DTO prosleđuju između slojeva ili kada je working set mali.
Šta se dešava na skali
Mikro-benchmarci na 1–10 miliona elemenata daju jednu sliku. Skaliranje na milijarde — drugačiju.
Tri od šest paterna na velikim podacima prelaze iz „optimizacije” u „nužnost”:
- B05 generator — na 100M, naivni — OOM. Generator završava.
- B06 kolonski layout — na 100M, row — OOM. Kolonski završava sken za 959 ms.
- B01 mmap — na 1B, JSON fixture fizički ne postoji (100+ GB). mmap učita 16 GB binara za 228 ms.
Dva paterna ostaju „samo optimizacije” bez obzira na skalu:
- B03 object pool: ~4× na bilo kojoj veličini.
- B04 lookup table: ~5× na bilo kojoj veličini.
Jedan patern je ispao uzak — štedi memoriju, ali nikad brzinu:
- B02 SplFixedArray: 38% manje memorije, uvek sporiji po brzini. Oba puta rade sve do 1B.
Ovo je verovatno najvažnije reframovanje u članku. Kada neko kaže „X je brži od Y”, to je tvrdnja o specifičnoj veličini podataka. Na malim podacima, polovina tvrdnji se lomi. Na velikim podacima, polovina se pretvara u „X radi, Y ne postoji”.
I još jedna stvar vredna posebne linije: JIT u PHP 8.4 nastavlja da jede optimizacije svakim release-om. Između run-ova na PHP 8.3.31 i 8.4.21, B03 je ubrzao sa 2.78× na 4.43×, B04 sa 3.75× na 5.81×. Nije bug — JIT se prosto nastavlja unapređivati. Za godinu dana, ovi brojevi će se opet pomeriti.
Tri pravila PHP performansi u 2026.
Iz ovih šest eksperimenata izronio je radni framework.
1. Veruj JIT-u.
Ne pokušavaj da ga nadmudriš na nivou sintakse. match vs switch — JIT kompajlira obe forme u istu jump tabelu. SplFixedArray vs upakovan array — JIT optimizuje obični array toliko agresivno da specijalizovana struktura gubi po brzini. FFI dereference vs $arr[$id] — JIT-kompajliran array access pobeđuje FFI cast-ove unutar hot loop-a.
Ako je tvoja optimizacija o tome „koji jezički konstrukt izabrati” — JIT je već napravio taj izbor za tebe.
2. Optimizuj ono što JIT ne vidi.
- Cache locality (B06: kolonski layout) — JIT ne upravlja memory layout-om. To je tvoja arhitektura.
- Allocation pressure (B03: object pool) — JIT ne eliminiše alokacije, samo ih ubrzava.
- I/O batching (batched INSERT od 1000 redova vs single-row) — JIT ne optimizuje round trip-ove ka Postgres-u.
- Cross-process resource sharing (B01: mmap + page cache) — JIT radi po procesu.
- Streaming vs materializacija (B05: generator) — JIT ti neće ukloniti 30 GB peak memorije.
3. Na dovoljno velikoj skali, optimizacije prestaju da budu optimizacije.
Postaju prag preživljavanja. Generator na 100K zapisa je 1.24× brži. Na 100M, on je jedini kod koji završava. Kolonski layout na 5M je 8.66× brži. Na 100M, on je jedini kod koji ne pojede 28 GB na overhead-u stdClass-a. mmap na 10M je sporiji po pozivu. Na 1B, on je jedini način da učitaš tabelu unutar sekunde.
To je strukturalno razmišljanje, ne sintaksičko. I to je ono što llama.cpp pretvara iz „teško optimizovane C++ biblioteke” u učeći artefakt za PHP developer-a. Ne „evo trikovi, ukradi ih”. Nego „evo granice jezika koje vidiš samo kad u njih udariš”.
Zaključak
Sav benchmark kod i reproducibilan Docker setup žive na GitHub-u: vbcherepanov/php-llamacpp-benchmarks. Pun sweep traje ~15 minuta (make all), uključujući case study koji uveze 100K redova u realan PostgreSQL.
Napomena o repozitorijumu: direktorijum data/ je gitignore-ovan — fixture (do 16 GB binarnih lookup fajlova na 1B tier-u) se generišu lokalno kroz make fixtures. Nemoj pokušavati da kloniraš sa njima.
Ako pronađeš bug u metodologiji ili hoćeš da dodaš tier — pošalji PR. Bavim se ovakvim stvarima kroz Braincore — Go-based meta-agent sa cost-aware routing-om i memorijskim slojem za AI coding agente. Ako su ovi benchmarci bili korisni i hoćeš da podržiš još ovakvih stvari, tu je Ko-fi.