Последние полгода я генерирую код через Claude Code по 6–8 часов в день. Не как эксперимент — как основной рабочий инструмент. У меня крутятся 7 кастомных саб-агентов, MCP-серверы, хуки, persistent memory. Я не теоретик, прочитавший пару постов и решивший высказаться.
И именно поэтому я говорю: большая часть AI-сгенерированного кода — это technical debt, который начинает гнить в момент коммита.
Не потому что модели плохие. Потому что их используют неправильно.
«Работает» — это не качество
Главная ловушка: ты описываешь задачу, получаешь 200 строк кода, запускаешь — работает. Тесты зелёные (если ты вообще их попросил). PR замержен. Все довольны.
Через три недели открываешь этот файл — и у тебя больше вопросов, чем ответов:
- Почему здесь три слоя абстракции для записи в одну таблицу?
- Почему сервис знает про HTTP-заголовки?
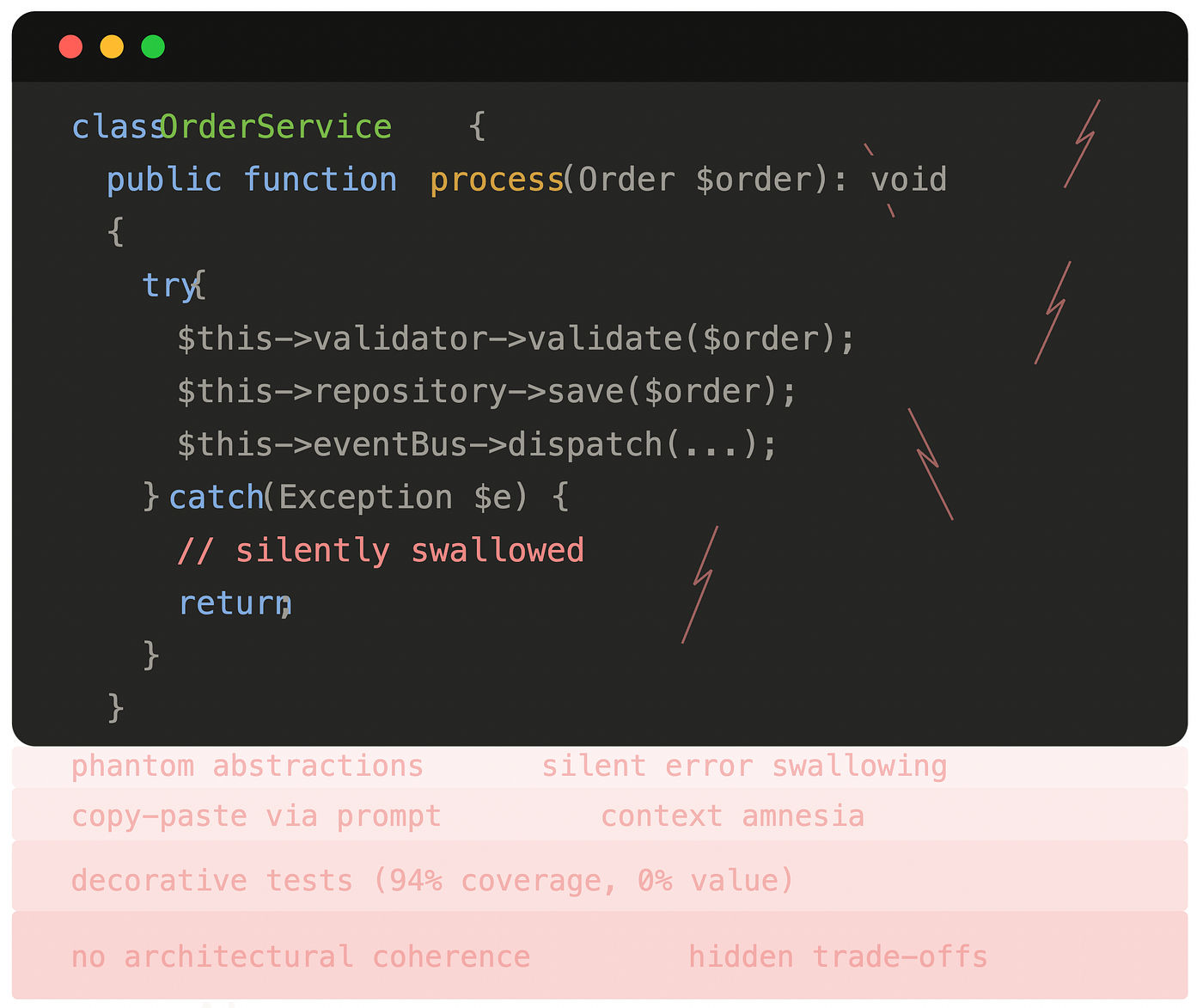
- Откуда взялся этот
catch (Exception $e), который молча проглатывает ошибки? - Почему DTO зеркалит структуру Entity 1:1, и зачем он вообще существует?
Модель не пишет плохой код намеренно. Она пишет правдоподобный код. Код, статистически похожий на то, что она видела в обучающей выборке. А обучающая выборка — это Stack Overflow, гитхаб-репы с 2 звёздами, туториалы junior-уровня и legacy-проекты на PHP 5.6.
Правдоподобно ≠ правильно. Правдоподобно ≠ поддерживаемо.
Конкретные паттерны разложения
Не буду теоретизировать. Вот что я вижу в реальных проектах каждую неделю:
1. Фантомные абстракции
Модель обожает создавать интерфейсы с одной реализацией, фабрики для объектов, которые создаются в одном месте, и сервисные слои, которые просто проксируют вызовы репозитория. Делает она это потому, что «так принято» в коде, на котором её обучали. Но абстракция без причины — это не архитектура. Это шум.
В одном PHP/Symfony-проекте на 15 сущностей я насчитал 47 AI-сгенерированных интерфейсов. Реальная потребность в полиморфизме была в 3 случаях.
2. Copy-paste через промпт
Люди копипастят руками. AI делает то же самое, только в масштабе. Ты просишь «такой же эндпоинт для заказов» — получаешь полную копию эндпоинта пользователей с переименованными переменными. Ни переиспользования, ни обобщения. Просто клон с другими именами.
Через полгода у тебя 30 контроллеров с одинаковыми обработкой ошибок, валидацией и пагинацией — все слегка разные. Потому что каждый сгенерирован как отдельный запрос.
3. Тихая деградация
Модель очень не любит возвращать ошибки. Она предпочтёт обернуть всё в try-catch, залогировать и вернуть пустой массив. Или null. Или дефолтное значение.
В Go это выглядит ещё хуже: if err != nil { return nil } — и о проблеме ты узнаёшь тремя слоями вызовов глубже, когда данные уже записались не туда.
Это не баг. Это паттерн: модель оптимизируется по «код компилируется и не падает», а не по «код корректно сообщает о проблемах».
4. Амнезия контекста
AI не помнит, что писал 40 промптов назад. Каждый новый запрос — чистый лист. У тебя могут оказаться два сервиса, делающих одно и то же; конфликтующие подходы к валидации в разных частях приложения; три разных способа работы с датами в одном проекте.
В монолите человек хотя бы видит соседний файл. AI видит только то, что ты ему показал. И строит в вакууме.
5. Декоративные тесты
Попроси AI написать тесты — получишь тесты. Красивые, структурированные, с моками и ассертами. Проблема: они тестируют реализацию, а не поведение. Они хрупкие. Они ломаются на любом рефакторинге. И создают иллюзию покрытия.
Я видел тест-сьют с 94% покрытия, который не поймал ни одной реальной ошибки бизнес-логики. Каждый тест проверял, что метод вызывает другой метод с правильными аргументами. Иначе говоря, они тестировали, что код написан так, как он написан. Спасибо, очень полезно.
Почему это хуже обычного техдолга
Обычный technical debt берётся осознанно. «Сделаем быстро сейчас, отрефакторим потом». Ты точно знаешь, где срезал угол. Знаешь, что сломается.
AI-долг — скрытый. Код выглядит чистым. Нейминг нормальный. Структура папок — как в учебнике. Никакой code-reviewer не придерётся. Но под капотом:
- нет единого архитектурного решения — просто набор локально-оптимальных фрагментов
- нет понимания бизнес-ограничений — только формальная корректность
- нет анализа trade-off’ов — просто «первый правдоподобный вариант»
Это как дом, где каждую комнату проектировал отдельный архитектор, не общавшийся с другими. Каждая комната нормальная. Жить в доме нельзя.
Так что, не использовать AI?
Нет. Я использую Claude Code каждый день, и моя скорость выросла кратно. Но я отношусь к AI-коду как к черновику, а не финальному результату.
Мой workflow:
- Архитектурные решения — мои. Я определяю структуру, слои, контракты между модулями. AI получает конкретные ограниченные задачи в рамках уже принятых решений.
- Ревью каждой генерации. Не «глянул» — а реальный review. Зачем этот интерфейс? Почему здесь три зависимости? Что будет, если этот сервис упадёт?
- Контекст — моя работа. Я веду
CLAUDE.md-файлы с архитектурными правилами для каждого проекта. Конвенции именования, подходы к обработке ошибок, запрещённые паттерны. Без этого каждая генерация — лотерея. - Рефакторить сразу. Не «потом». Сразу после генерации — снять лишние абстракции, унифицировать с остальным кодом, проверить edge cases.
- AI не пишет бизнес-логику с нуля. Он реализует то, что я уже продумал. Разница как между «нарисуй мне дом» и «построй по этим чертежам».
Итог
AI-генерация кода — не silver bullet и не конец профессии. Это мощный инструмент, который в руках инженера ускоряет работу, а в руках prompt-оператора генерирует technical debt со скоростью, ранее физически невозможной.
Разница между «я использую AI для разработки» и «AI разрабатывает за меня» — это разница между инструментом и костылём.
Если ты не можешь объяснить, зачем существует каждая строка в сгенерированном коде — ты не программируешь. Ты копишь долг, который кому-то придётся выплачивать. Возможно, тебе. Через три месяца. С процентами.
15+ лет в продакшене. PHP/Symfony, Go, Vue/Nuxt, PostgreSQL. Пишу о реальном опыте использования AI-инструментов в повседневной разработке.