Poslednjih šest meseci generišem kod kroz Claude Code 6–8 sati dnevno. Ne kao eksperiment — kao primarni radni alat. Pokrećem 7 prilagođenih sub-agenata, MCP servere, hookove, persistent memory. Nisam neki teoretičar koji je pročitao par blog postova i odlučio da ima mišljenje.
I upravo zato kažem ovo: većina AI-generisanog koda je tehnički dug koji počinje da truli u trenutku kad uđe u commit.
Ne zato što su modeli loši. Zato što ih ljudi koriste pogrešno.
„Radi” nije kvalitet
Glavna zamka: opišeš zadatak, dobiješ 200 linija koda, pokreneš — radi. Testovi su zeleni (ako si ih uopšte tražio). PR je merge-ovan. Svi su srećni.
Tri nedelje kasnije otvoriš taj fajl, i imaš više pitanja nego odgovora:
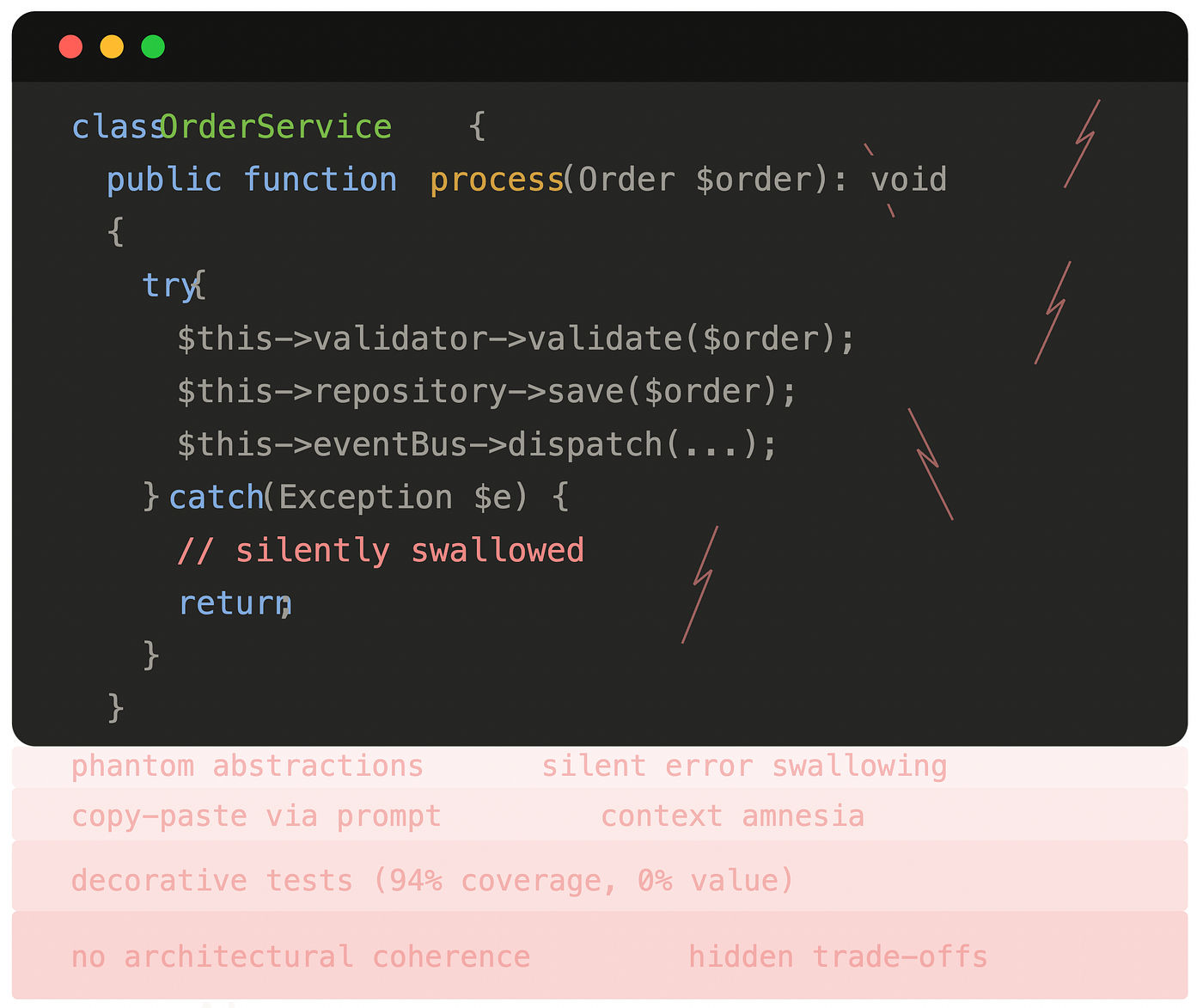
- Zašto su tu tri sloja apstrakcije za pisanje u jednu tabelu?
- Zašto servis zna za HTTP zaglavlja?
- Odakle je došao ovaj
catch (Exception $e)koji tiho guta greške? - Zašto DTO ogleda strukturu Entity-ja 1:1, i čemu uopšte služi?
Model ne piše loš kod namerno. On piše uverljiv kod. Kod koji statistički liči na ono što je video u trening podacima. A trening podaci su Stack Overflow, GitHub repozitorijumi sa 2 zvezdice, junior-level tutorijali i legacy projekti na PHP 5.6.
Uverljivo ≠ tačno. Uverljivo ≠ održivo.
Konkretni patterni propadanja
Neću da teoretišem. Evo šta vidim u realnim projektima svake nedelje:
1. Fantomske apstrakcije
Model voli da pravi interfejse sa jednom implementacijom, fabrike za objekte koji se instanciraju na jednom mestu, i servisne slojeve koji samo proksiraju pozive ka repozitorijumu. Radi to zato što je „tako uobičajeno” u kodu na kome je treniran. Ali apstrakcija bez razloga nije arhitektura — to je šum.
U jednom PHP/Symfony projektu sa 15 entiteta, izbrojao sam 47 AI-generisanih interfejsa. Stvarna potreba za polimorfizmom postojala je u 3 slučaja.
2. Copy-paste kroz prompt
Ljudi copy-paste-uju ručno. AI radi isto, ali u razmeri. Tražiš „sličan endpoint za narudžbine” — dobiješ punu kopiju users endpoint-a sa zamenjenim imenima. Bez ponovnog korišćenja. Bez generalizacije. Samo klon sa drugačijim imenima promenljivih.
Šest meseci kasnije imaš 30 kontrolera sa identičnim error handling-om, validacijom i strukturom paginacije — sve blago drugačije. Jer je svaki generisan kao nezavisan zahtev.
3. Tiha degradacija
Modelu se zaista ne sviđa da vraća greške. Radije će sve obaviti u try-catch, logovati i vratiti prazan niz. Ili null. Ili default vrednost.
U Go-u izgleda još gore: if err != nil { return nil } — i o problemu saznaješ tri sloja poziva dublje, kad su podaci već zapisani na pogrešno mesto.
Ovo nije bug. To je pattern: model optimizuje za „kod se kompajlira i ne ruši se”, ne za „kod ispravno prijavljuje probleme”.
4. Amnezija konteksta
AI ne pamti šta je napisao 40 promptova ranije. Svaki novi zahtev je čista tabla. Možeš završiti sa dva servisa koji rade istu stvar, konfliktnim pristupima validaciji u različitim delovima aplikacije, tri različita načina rada sa datumima u jednom projektu.
U monolitu čovek bar vidi susedni fajl. AI vidi samo ono što si mu pokazao. I gradi u vakuumu.
5. Dekorativni testovi
Traži od AI-ja da napiše testove — dobićeš testove. Lepe, dobro strukturisane, sa mock-ovima i assertion-ima. Problem: testiraju implementaciju, ne ponašanje. Krhki su. Lome se na svakom refaktorisanju. I stvaraju iluziju coverage-a.
Video sam test-suite sa 94% coverage-a koji nije uhvatio nijednu pravu grešku biznis logike. Svaki test je proveravao da metoda poziva drugu metodu sa pravim argumentima. Drugim rečima, testirali su da je kod napisan onako kako je napisan. Hvala, vrlo korisno.
Zašto je ovo gore od običnog tech debt-a
Običan tehnički dug se uzima svesno. „Hajde da uradimo brzo sad, refaktorisaćemo kasnije”. Tačno znaš gde si presekao ćošak. Znaš šta će se polomiti.
AI tech debt je skriven. Kod izgleda čisto. Naming je u redu. Struktura foldera — kao iz udžbenika. Nijedan code reviewer neće naći zamerku. Ali ispod:
- Nema jedinstvene arhitektonske odluke — samo skup lokalno-optimalnih fragmenata
- Nema razumevanja biznis ograničenja — samo formalna ispravnost
- Nema analize trade-off-ova — samo „prvi uverljiv pristup”
To je kao kuća gde je svaku sobu projektovao drugačiji arhitekta koji nikad nije razgovarao sa ostalima. Svaka soba je u redu. Kuća kao celina je nenastanjiva.
Znači, ne koristiti AI?
Ne. Koristim Claude Code svakodnevno, i moja brzina je drastično porasla. Ali se prema AI kodu odnosim kao prema draftu, ne kao prema finalnom rezultatu.
Moj workflow:
- Arhitektonske odluke su moje. Definišem strukturu, slojeve, ugovore između modula. AI dobija konkretne, ograničene zadatke unutar već donetih odluka.
- Pregled svake generacije. Ne „letimično pogledao” — pravi review. Zašto ovaj interfejs? Zašto tri zavisnosti ovde? Šta će se desiti ako ovaj servis padne?
- Kontekst je moj posao. Vodim
CLAUDE.mdfajlove sa arhitektonskim pravilima za svaki projekat. Konvencije imenovanja, pristupi obradi grešaka, zabranjeni patterni. Bez ovoga, svaka generacija je lutrija. - Refaktoriši odmah. Ne „kasnije”. Odmah posle generacije — skini suvišne apstrakcije, ujedini sa ostatkom kodbase-a, proveri edge case-ove.
- AI ne piše biznis logiku iz nule. On implementira ono što sam već promislio. Razlika je između „nacrtaj mi kuću” i „izgradi po ovom projektu”.
Suština
AI generacija koda nije srebrni metak, niti je kraj profesije. To je moćan alat koji u rukama inženjera ubrzava rad, a u rukama prompt-operatera generiše tehnički dug brzinom koja je ranije bila fizički nemoguća.
Razlika između „koristim AI za razvoj” i „AI razvija umesto mene” je razlika između alata i štake.
Ako ne možeš da objasniš zašto svaka linija u generisanom kodu postoji — ne programiraš. Gomilaš dug koji će neko morati da otplati. Možda ti. Za tri meseca. Sa kamatom.
15+ godina u produkciji. PHP/Symfony, Go, Vue/Nuxt, PostgreSQL. Pišem o realnom iskustvu sa AI alatima u svakodnevnom razvoju.